Relational Data Modeling
This section considers the example social media app introduced in the previous section and discusses how it could be modeled with a traditional relational data model, such as those used by SQL databases.
With relational data models, you create lists of each type of data in tables,
and then add columns in those tables to track the attributes of that table’s
data. Looking back on our data, we remember that we have three main types,
People, Posts, and Comments
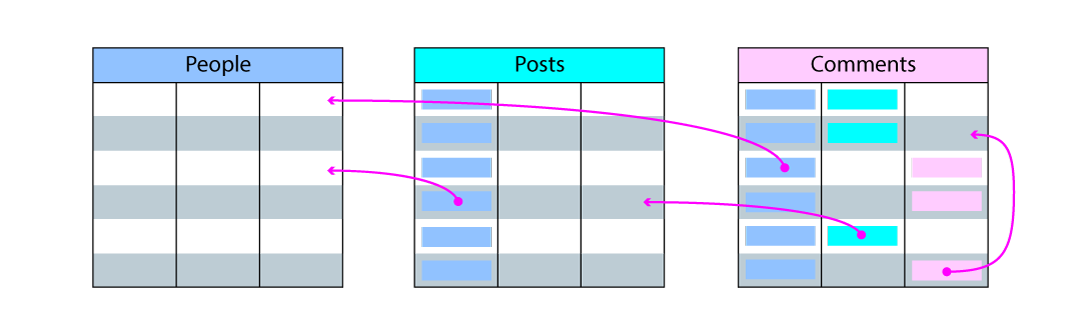
To define relationships between records in two tables, a relational data model uses numeric identifiers called foreign keys, that take the form of table columns. Foreign keys can only model one-to-many relationship types, such as the following:
- The relationship from
PoststoPeople, to track contributors (authors, editors, etc.) of aPost - The relationship from
CommentstoPeople, to track the author of the comment - The relationship from
CommentstoPosts, to track on which post comments were made - The relationship between rows in the
Commentstable, to track comments made in reply to other comments (a self-reference relationship)
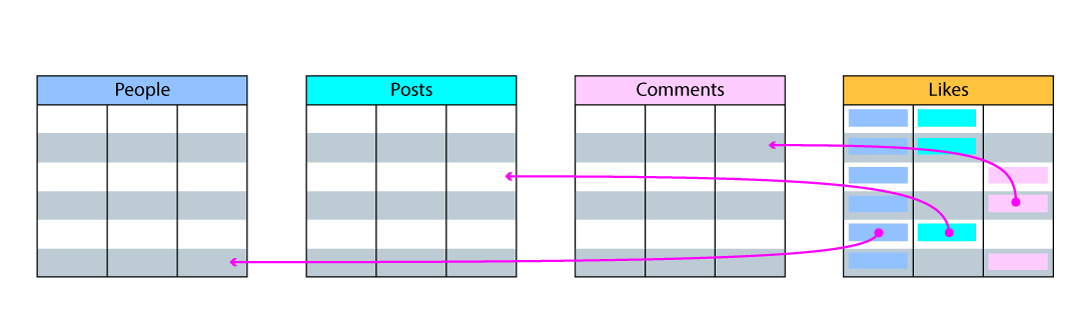
The limitations of foreign keys become apparent when your app requires you to model many-to-many relationships. In our example app, a person can like many posts or comments, and posts and comments can be liked by many people. The only way to model this relationship in a relational database is to create a new table. This so-called pivot table usually does not store any information itself, it just stores links between two other tables.
In our example app, we decided to limit the number of tables by having a
single “Likes” table instead of having people_like_posts and
people_like_comments tables. None of these solutions is perfect, though, and
there is a trade-off between having a lower table count or having more
empty fields in our tables (also known as “sparse data”).
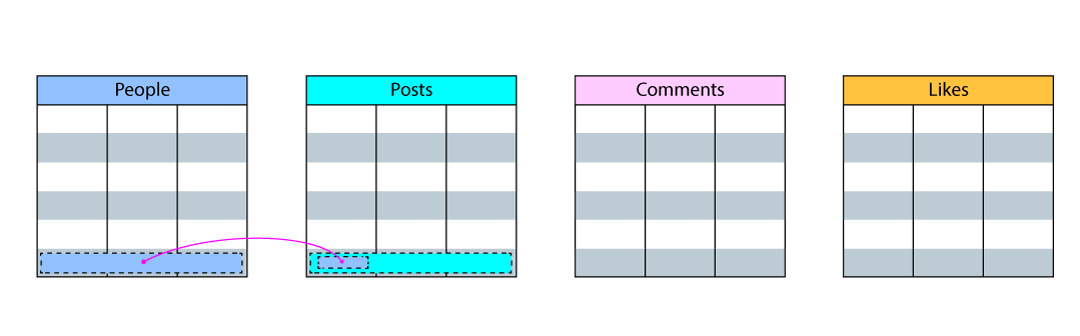
Because foreign keys cannot be added in reference to entities that do not exist,
adding new posts and authors requires additional work. To add a new post and a
new author at the same time (in the Posts and People tables), we must first add
a row to the People table and then retrieve their primary key and associate it
with the new row in the Posts table.
By now, you might ask yourself: How does a relational model expand to handle new data, new types of data, and new data relationships?
When new data is added to the model, the model will change to accept the data. The simplest type of change is when you add a new row to a table. The new row adopts all of the columns from the table. When you add a new property to a table, the model changes and adds the new property as a column on every existing and future row for the table. And when you add a new data type to the database, you create a new table with its own pre-defined columns. This new data type might link to existing tables or need more pivot tables for a new many-to-many relationship. So, with each data type added to your relational data model, the need to add foreign keys and pivot tables increases, making support for querying every potential data relationship increasingly unwieldy.
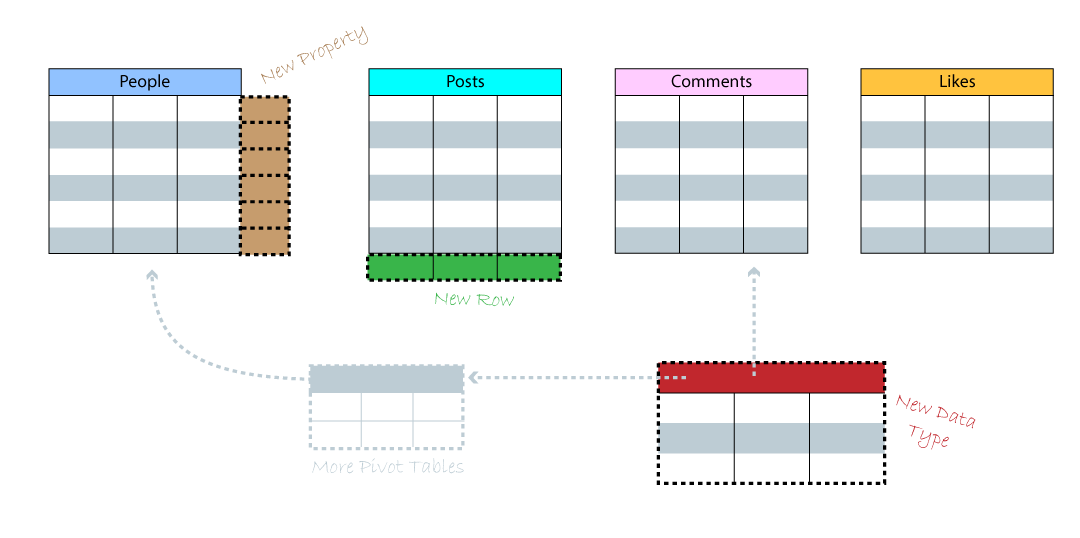
Properties are stored as new columns and relationships require new columns and sometimes new pivot tables. Changing the schema in a relational model directly effects the data that is held by the model, and can impact database query performance.