Graph Data Modeling
In this section we will take our example social media app and see how it could be modeled in a graph.
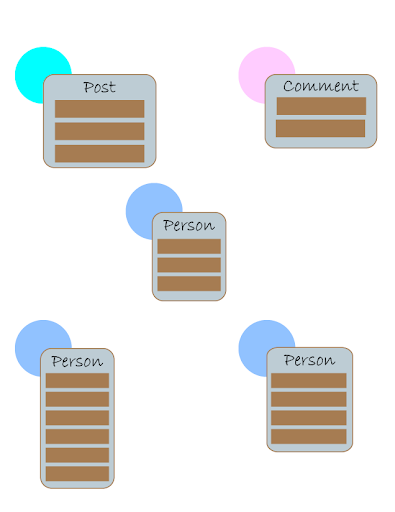
The concept of modeling data in a graph starts by placing dots, which represent
nodes. Nodes can have one or more predicates (properties). A person may have
predicates for their name, age, and gender. A post might have a predicate value
showing when it was posted, and a value containing the contents of the post. A
comment would most likely have a predicate containing the comment string.
However, any one node could have other predicates that are not contained on any
other node. Each node represents an individual item, hence the singular naming
structure.
As graphs naturally resemble the data you are modeling, the individual nodes can be moved around this conceptual space to clearly show the relationships between these data nodes. Relationships are formed in graphs by creating an edge between them. In our app, a post has an author, a post can have comments, a comment has an author, and a comment can have a reply.
For sake of illustration we will also show the family tree information. The
father and the mother are linked together with a spouse edge, and both parents
are related to the child along a child edge.
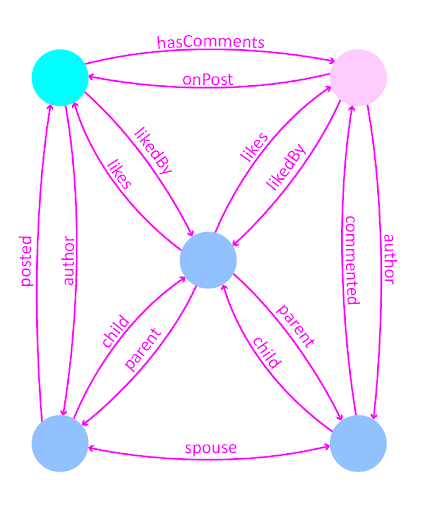
With a graph, you can also name the inverse relations. From here we can quickly
see the inverse relationships. A Post has an Author and a Person has Posts. A
Post has Comments and a Comment is on a Post. A Comment has an Author, and a
Person has Comments. A Parent has a Child, and a Child has a Parent.
You create many-to-many relationships in the same way that you make one-to-many relationships, with an edge between nodes.
Adding groups of related data occurs naturally within a graph. The data is sent as a complete object instead of separate pieces of information that needs to be connected afterwards. Adding a new person and a new post to our graph is a one-step process. New data coming in does not have to be related to any existing data. You can insert this whole data object with 3 people, a post, and a comment; all in one step.
When new data is added to the model, the model will change to accept the data. Every change to a graph model is received naturally. When you add a new node with a data type, you are simply creating a new dot in space and applying a type to it. The new node does not include any predicates or relationships other than what you define for it. When you want to add a new predicate onto an existing data type, the model changes and adds the new property onto the items that you define. Other items not specifically given the new property type are not changed. When you add a new data type to the database, a new node is created, ready to receive new edges and predicates.
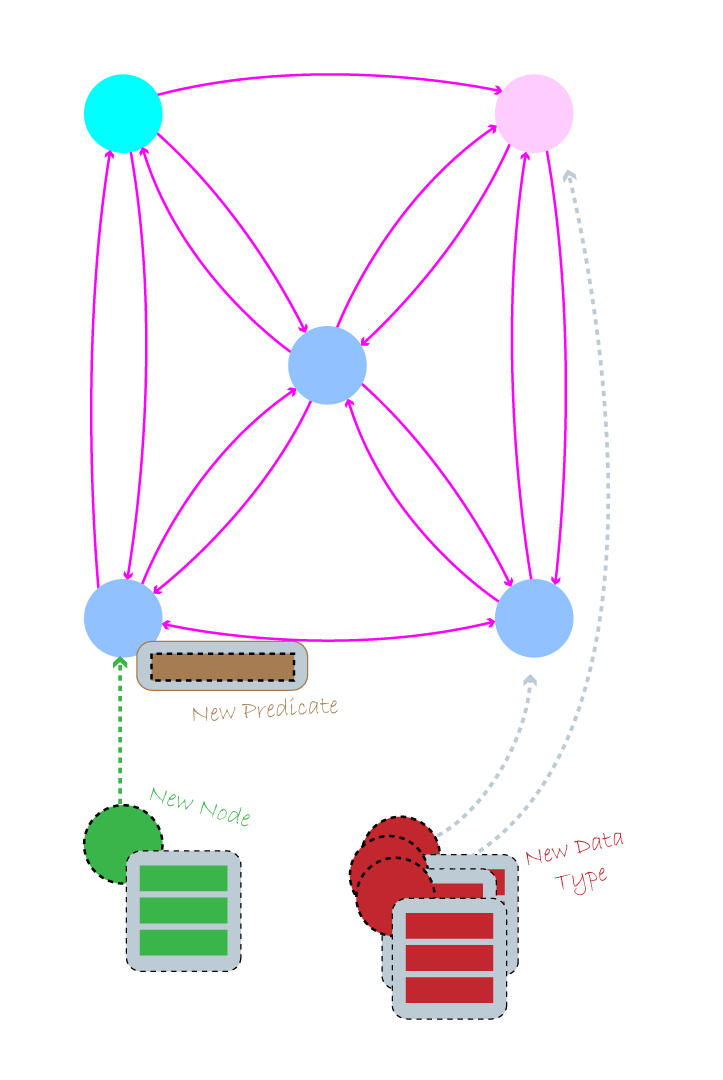
The key to remember when modeling a graph is to focus on the relationships between nodes. In a graph you can change the model without affecting the underlying data. Because the graph is stored as individual nodes, you can adjust predicates of individual nodes, create edges between sets of nodes, and add new node types without affecting any of the other nodes.